
Visualizing future concepts with body input and AI
We all saw the wave of AI tools conquering the creative industry in the past year. The disruptive technology forced everybody in this profession to feel enabled or threatened by the new workflows that opened up. For us, it was clear that we wanted to fuse the technology with our roots in creating interactive installations. The possibility of giving users something at hand to form and create their own imagination instantly is vastly inspiring to us. We aimed to define a collaborative workflow between the user and AI, which is guided but still gives enough creative freedom. An intuitive interaction and the ability to use one's body as a sculpting tool were vital for our application.
Check the article also on behance.

Future telling
In the UI and visual design, we wanted to reflect the favorable but also overly techno-optimistic view of most people regarding new technological developments. Some are chasing after innovative ideas hoping they will solve all existing problems. Therefore, the stylistic choice of integrating elements from fortune telling with tarot cards felt fitting. The decorative elements inspired by the art nouveau style also provided a potent analogy for the novel aesthetic of AI art.

Body-to-image generation in an installation context
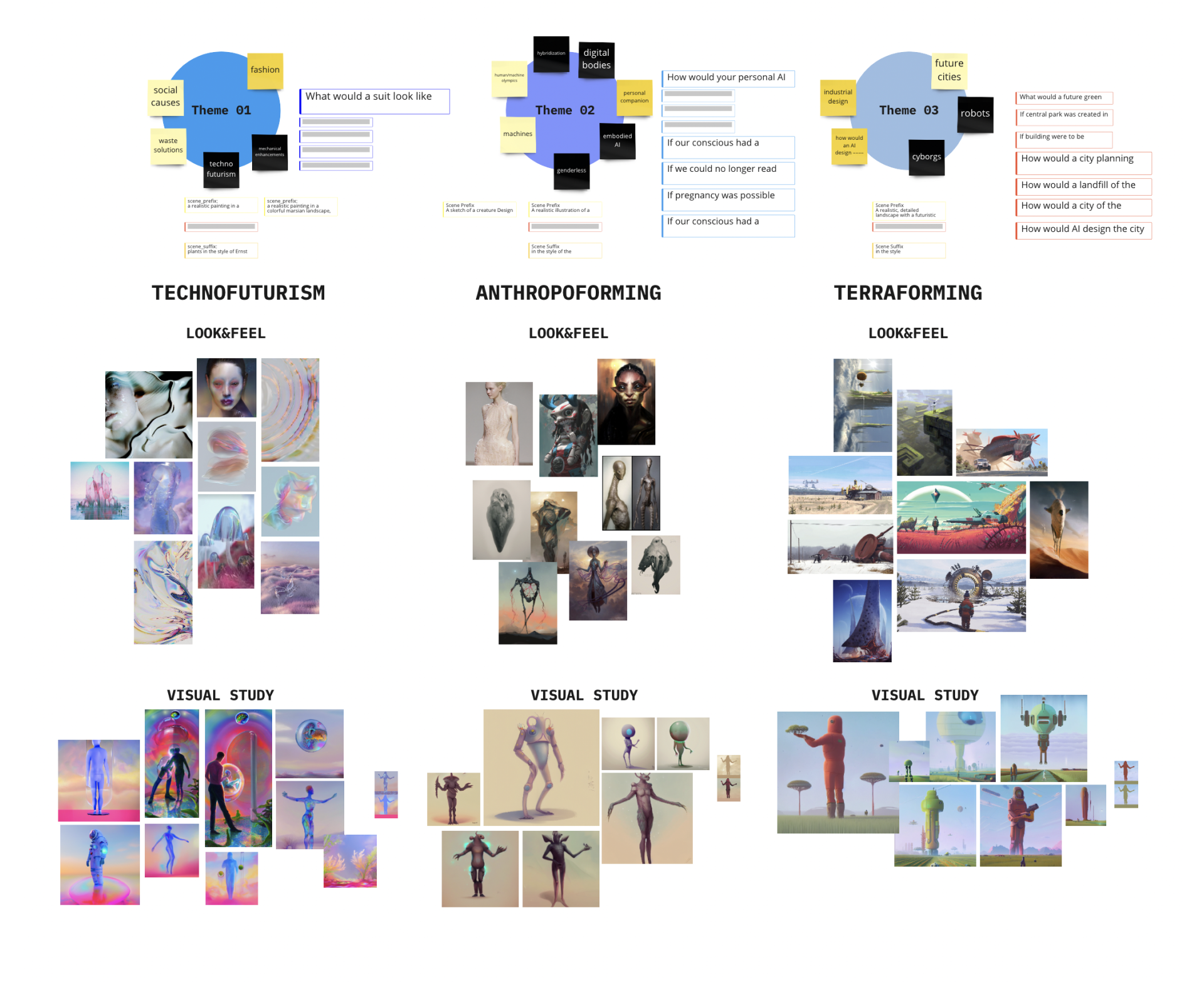
As a deep learning generator, we decided on Stable-Diffusion as it allowed us to have great control over the generation-parameters. In the following we defined a conceptual and visual framework to guide user and image generation to a cohesive result. The main quest was to answer questions about an individual, speculative product in the future and input the answer through a touch-interface. To optimize the user experience, we gave each visitor three umbrella themes. The user's answer was then used as a text-to-image prompt for the image generation. For each umbrella theme we developed a distinctive visual direction.
Controlling image diffusion in a particular direction is the most time-consuming and challenging part of using deep learning tools. Apart from thought-through prompt design and a collection of well-working terms, it is essential to be flexible about the result. The more precisely the imagined concept is described, the better the generation will be. It is recommended to work with overlapping concepts since only a limited amount of pixels can be used for the generation. Too many contradicting ideas are competing for a limited space. Therefore, we developed a prompt pre- and -suffix connected to the umbrella theme.These prompts were not apparent on the front end and helped us create a cohesive look and feel for each theme by wrapping them around the user's prompt. The concept phase's assembled mood boards helped us find the best fitting terms.

In addition to the text input, we also worked with input images for the fore- and background. That way, we created more variation for the denoising process happening during image diffusion. The input images made it likewise possible to define color schemes for each theme.
Our most important input was the shape of the user's body, tracked via an infrared camera. This method enabled it to influence the overall composition playfully. The body was functioning as a mask, revealing the defined foreground image set. In the interface, the users could see the shape of their body as a shadow silhouette. The influence was visible after a few seconds revealing the generated result. After playing around and testing several text prompts combined with their own body input, the three favorite outcomes could be selected and added to the idle mode collection of fictional futures.
Technical challenges
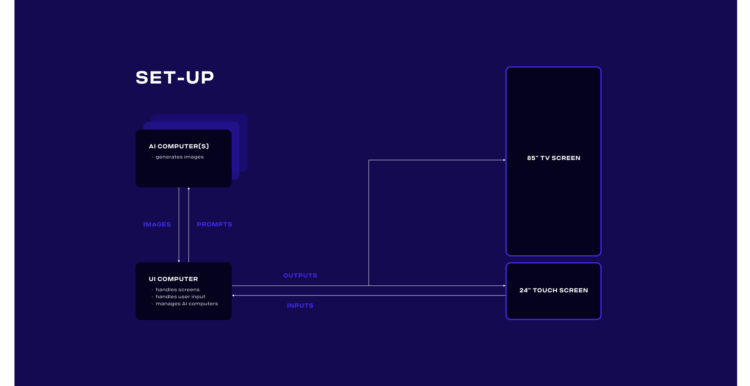
Giving the user direct feedback to their inputs was a critical aspect of the experience. We, therefore, split the image generation onto a dedicated high-end PC with a self-hosted Stable Diffusion installation and settings that allowed us to render an image within 4-8 seconds. The user interacted with a separate client that rendered the UI and managed the render tasks. Adding further render PCs would have allowed us to increase the frame rate even further.
The final setup would allow users to create an animation from their generated images. Still, long render times and the lack of direct animation support in the selected Stable-Diffusion model made it impractical.
Paving the way for an actual project
The Fictional-Future experience ran during our demodern showroom. It generated so much interest that our client MINI chose to integrate this technology into the Sydney WorldPride Month event for the MINIverse, where users could generate their own LGBTQAI+-themed images from within the MINIverse in their web browser or mobile device. Find impressions of the Level here.


